




Belati is tool for Collecting Public Data & Public Document from Website and other service for OSINT purpose. This tools is inspired by Foca and Datasploit for OSINT.
What Belati can do?
- Whois(Indonesian TLD Support)
- Banner Grabbing
- Subdomain Enumeration
- Service Scanning for all Subdomain Machine
- Web Appalyzer Support
- DNS mapping / Zone Scanning
- Mail Harvester from Website & Search Engine
- Mail Harvester from MIT PGP Public Key Server
- Scrapping Public Document for Domain from Search Engine
- Fake and Random User Agent ( Prevent from blocking )
- Proxy Support for Harvesting Emails and Documents
- Public Git Finder in domain/subdomain
- Public SVN Finder in domain/subdomain
- Robot.txt Scraper in domain/subdomain
- Gather Public Company Info & Employee
- SQLite3 Database Support for storing Belati Results
- Setup Wizard/Configuration for Belati
TODO
- Automatic OSINT with Username and Email support
- Organization or Company OSINT Support
- Collecting Data from Public service with Username and Email for LinkedIn and other service.
- Setup Wizard for Token and setting up Belati
- Token Support
- Email Harvesting with multiple content(github, linkedin, etc)
- Scrapping Public Document with multiple search engine(yahoo, yandex, bing etc)
- Metadata Extractor
- Web version with Django
- Scanning Report export to PDF
- domain or subdomain reputation checker
- Reporting Support to JSON, PDF
- Belati Updater
Install/Usage
git clone https://github.com/aancw/Belati.git
cd Belati
git submodule update --init --recursive --remote
pip install -r requirements.txt #please use pip with python v2
sudo su
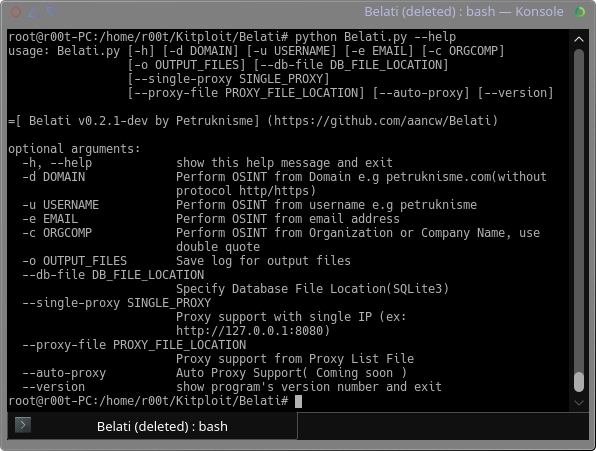
python Belati.py --helpTested On
Ubuntu 16.04 x86_64 Arch Linux x86_64 CentOS 7
Python Requirements
This tool not compatible with Python 3. So use python v2.7 instead!
Why Need Root Privilege?
Nmap need Root Privilege. You can add sudo or other way to run nmap without root privilege. It's your choice ;)
Reference -> https://secwiki.org/w/Running_nmap_as_an_unprivileged_user
Don't worry. Belati still running when you are run with normal user ;)
Dependencies
- urllib2
- dnspython
- requests
- argparse
- texttable
- python-geoip-geolite2
- python-geoip
- dnsknife
- termcolor
- colorama
- validators
- tqdm
- tldextract
- fake-useragent
System Dependencies
For CentOS/Fedora user, please install this:
yum install gcc gmp gmp-devel python-develLibrary
- python-whois
- Sublist3r
- Subbrute
- nmap
- git
- sqlite3
Notice
This tool is for educational purposes only. Any damage you make will not affect the author. Do It With Your Own Risk!
Author
Aan Wahyu a.k.a Petruknisme(https://petruknisme.com)







